|
|
||
|---|---|---|
| pics | ||
| .gitignore | ||
| LICENSE-CC | ||
| LICENSE-GPL | ||
| README.md | ||
| wut | ||
| wut-audio-archive | ||
| wut-compare | ||
| wut-compare-all | ||
| wut-compare-tx | ||
| wut-compare-txmode | ||
| wut-compare-txmode-csv | ||
| wut-dl-sort | ||
| wut-dl-sort-tx | ||
| wut-dl-sort-txmode | ||
| wut-ml | ||
| wut-ml-load | ||
| wut-ml-save | ||
| wut-obs | ||
| wut-review-staging | ||
| wut-water | ||
| wut-water-range | ||
README.md
satnogs-wut
The goal of satnogs-wut is to have a script that will take an observation ID and return an answer whether the observation is "good", "bad", or "failed".
Good Observation
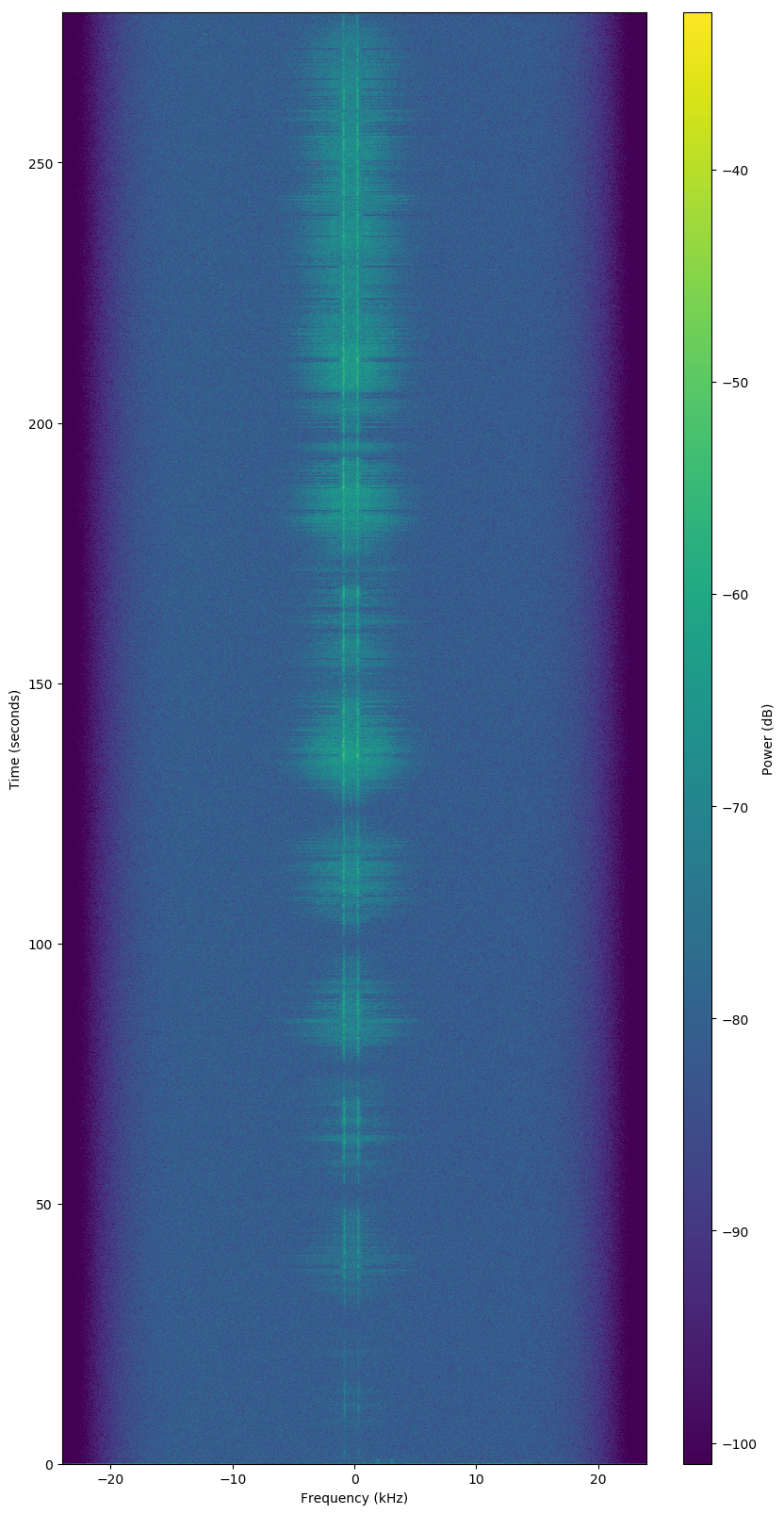
Bad Observation
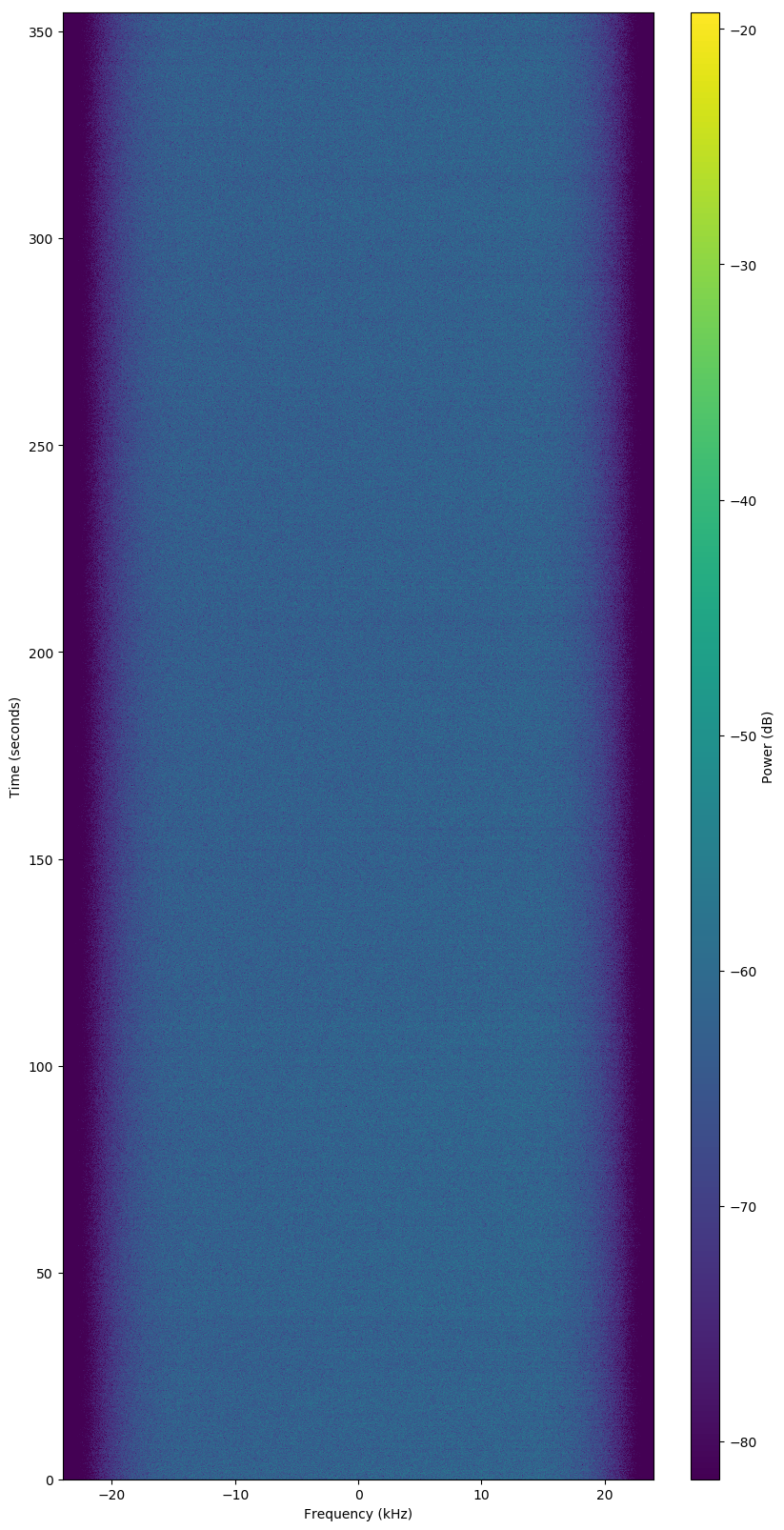
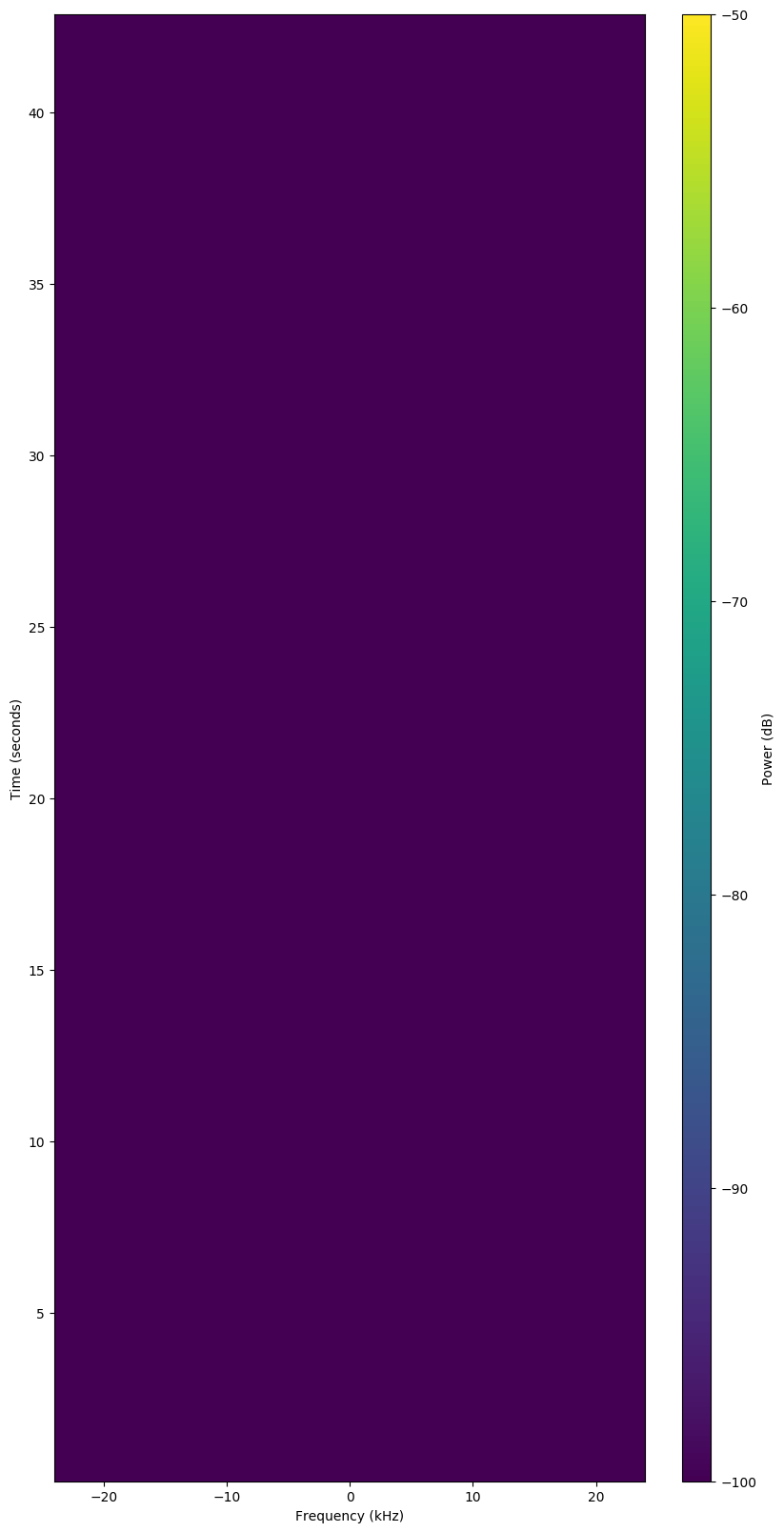
Failed Observation
Machine Learning
The system at present is built upon the following:
- Debian
- Tensorflow
- Keras
Learning/testing, results are inaccurate.
wut?
The following scripts are in the repo:
wut--- Feed it an observation ID and it returns if it is a "good", "bad", or "failed" observation.wut-compare--- Compare an observations' current presumably human vetting with awutvetting.wut-compare-all--- Compare all the observations indownload/withwutvettings.wut-compare-tx--- Compare all the observations indownload/withwutvettings using selected transmitter UUID.wut-compare-txmode--- Compare all the observations indownload/withwutvettings using selected encoding.wut-dl-sort--- Populatedata/dir with waterfalls fromdownload/.wut-dl-sort-tx--- Populatedata/dir with waterfalls fromdownload/using selected transmitter UUID.wut-dl-sort-txmode--- Populatedata/dir with waterfalls fromdownload/using selected encoding.wut-ml--- Main machine learning Python script using Tensorflow and Keras.wut-obs--- Download the JSON for an observation ID.wut-review-staging--- Review all images indata/staging.wut-water--- Download waterfall for an observation ID todownload/[ID].wut-water-range--- Download waterfalls for a range of observation IDs todownload/[ID].
Installation
Most of the scripts are simple shell scripts with few dependencies.
Setup
The scripts use files that are ignored in the git repo. So you need to create those directories:
mkdir -p download
mkdir -p data/train/good
mkdir -p data/train/bad
mkdir -p data/train/failed
mkdir -p data/val/good
mkdir -p data/val/bad
mkdir -p data/val/failed
mkdir -p data/staging
mkdir -p data/test/unvetted
Debian Packages
You'll need curl and jq, both in Debian's repos.
apt update
apt install curl jq
Machine Learning
For the machine learning scripts, like wut-ml, both Tensorflow
and Keras need to be installed. The versions of those in Debian
didn't work for me. IIRC, for Tensorflow I built a pip of
version 2.0.0 from git and installed that. I installed Keras
with pip. Something like:
# XXX These aren't the exact commands, need to check...
apt update
# deps...
apt install python3-pip ...
# Install bazel or whatever their build system is
# Install Tensorflow
git clone tensorflow...
cd tensorflow
./configure
# run some bazel command
dpkg -i /tmp/pkg_foo/*.deb
apt update
apt -f install
# Install Keras
pip3 install --user keras
# A million other commands....
Usage
The main purpose of the script is to evaluate an observation, but to do that, it needs to build a corpus of observations to learn from. So many of the scripts in this repo are just for downloading and managing observations.
The following steps need to be performed:
-
Download waterfalls and JSON descriptions with
wut-water-range. These get put in thedownloads/[ID]/directories. -
Organize downloaded waterfalls into categories (e.g. "good", "bad", "failed"). Use
wut-dl-sortscript. The script will sort them into their respective directories under:data/train/good/data/train/bad/data/train/failed/data/val/good/data/val/bad/data/val/failed/
-
Use machine learning script
wut-mlto build a model based on the files in thedata/trainanddata/valdirectories. -
Rate an observation using the
wutscript.
ml.spacecruft.org
This server is processing the data and has directories available to sync.
Data Caching Downloads
The scripts are designed to not download a waterfall or make a JSON request
for an observation it has already requested. The first time an observation
is requested, it is downloaded from the SatNOGS network to the download
directory. That download directory is the download cache.
The data directory is just temporary files,mostly linked from the
downloads directory. Files in the data directory are deleted by many
scripts, so don't put anything you want to keep in there.
SatNOGS Observation Data Mirror
The downloaded waterfalls are available below via http and rsync.
Use this instead of downloading from SatNOGS to save their bandwidth.
# Something like:
wget --mirror https://ml.spacecruft.org/download
# Or with rsync:
mkdir download
rsync -ultav rsync://ml.spacecruft.org/download/ download/
TODO / Brainstorms
This is a first draft of how to do this. The actual machine learning process hasn't been looked at at all, except to get it to generate an answer. It has a long ways to go. There are also many ways to do this besides using Tensorflow and Keras. Originally, I considered using OpenCV. Ideas in no particular order below.
General
General considerations.
-
Use Open CV.
-
Use something other than Tensorflow / Keras.
-
Do mirror of
network.satnogs.organd do API calls to it for data. -
Issues are now available here:
Tensorflow / Keras
At present Tensorflow and Keras are used.
-
Learn Keras / Tensorflow...
-
What part of image is being evaluated?
-
Re-evaluate each step.
-
Right now the prediction output is just "good" or "bad", needs "failed" too.
-
Give confidence score in each prediction.
-
Visualize what ML is looking at.
-
Separate out good/bad/failed by satellite, transmitter, or encoding. This way "good" isn't considering a "good" vetting to be a totally different encoding. Right now, it is considering as good observations that should be bad...
-
If it has a low confidence, return "unknown" instead of "good" or "bad".
Caveats
This is nearly the first machine learning script I've done, I know little about radio and less about satellites, and I'm not a programmer.
Source License / Copying
Main repository is available here:
License: CC By SA 4.0 International and/or GPLv3+ at your discretion. Other code licensed under their own respective licenses.
Copyright (C) 2019, 2020, Jeff Moe