8.2 KiB
wut?
wut --- What U Think? SatNOGS Observation AI.
Website:
satnogs-wut
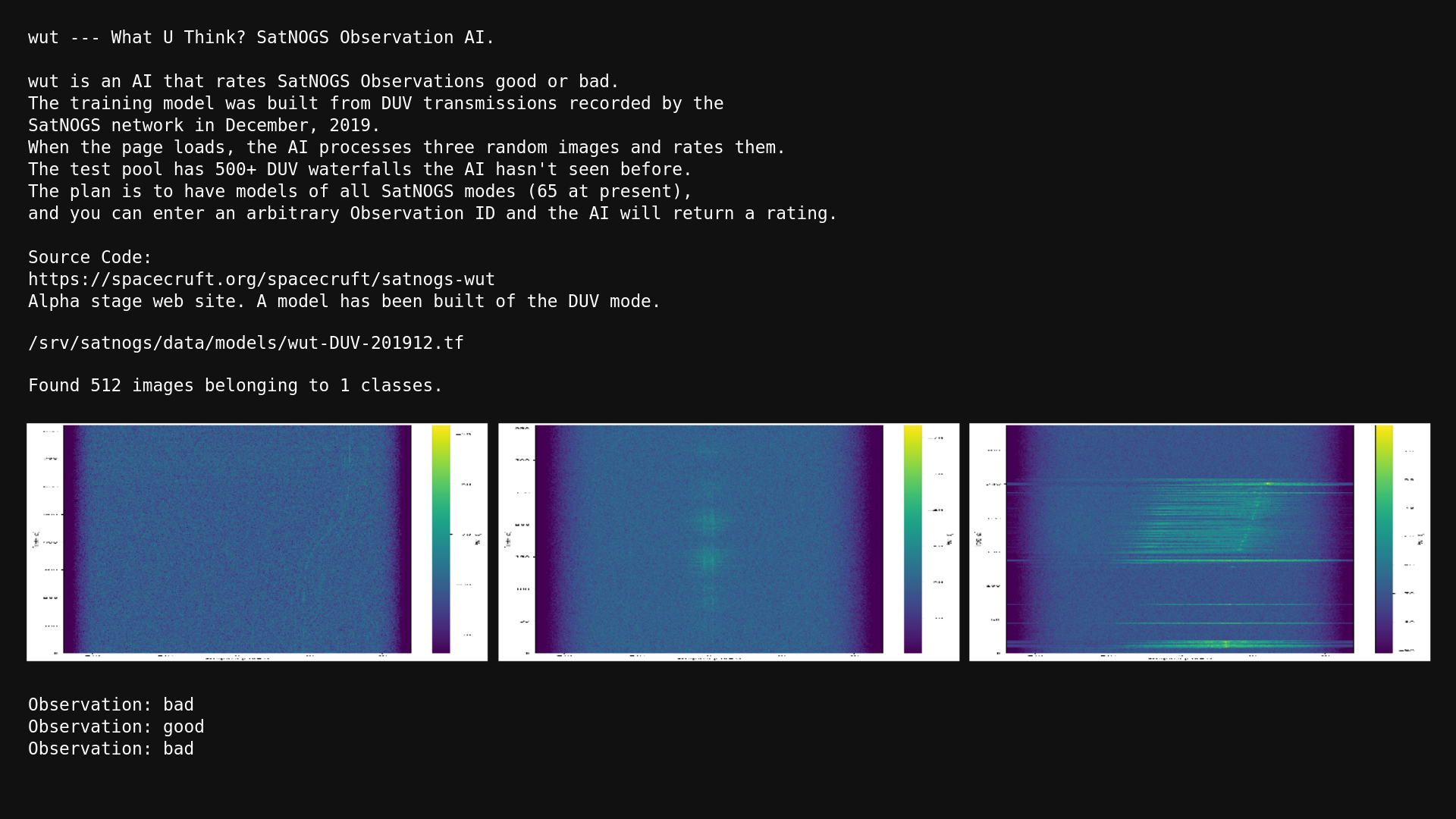
The goal of satnogs-wut is to have a script that will take an observation ID and return an answer whether the observation is "good", "bad", or "failed".
Good Observation
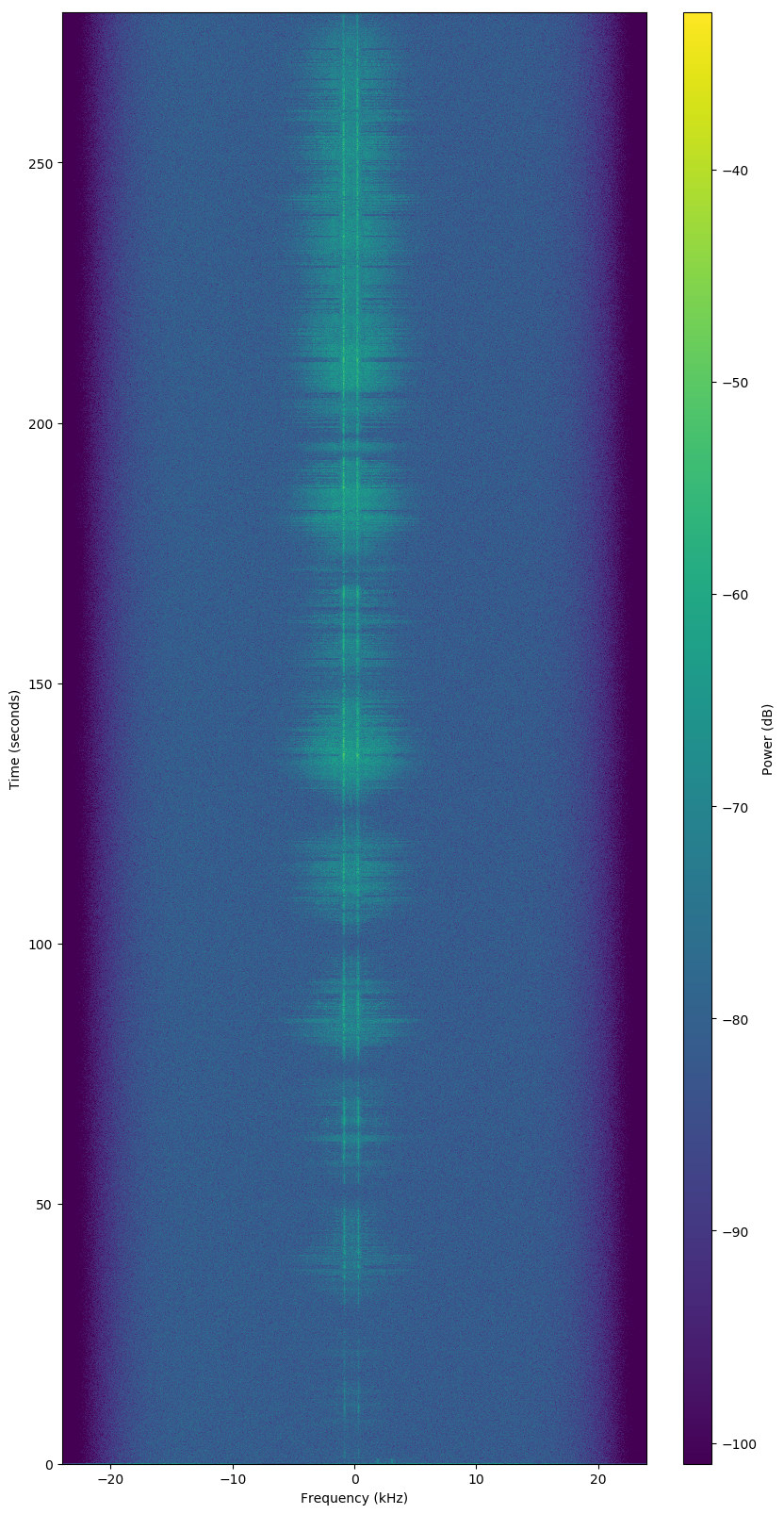
Bad Observation
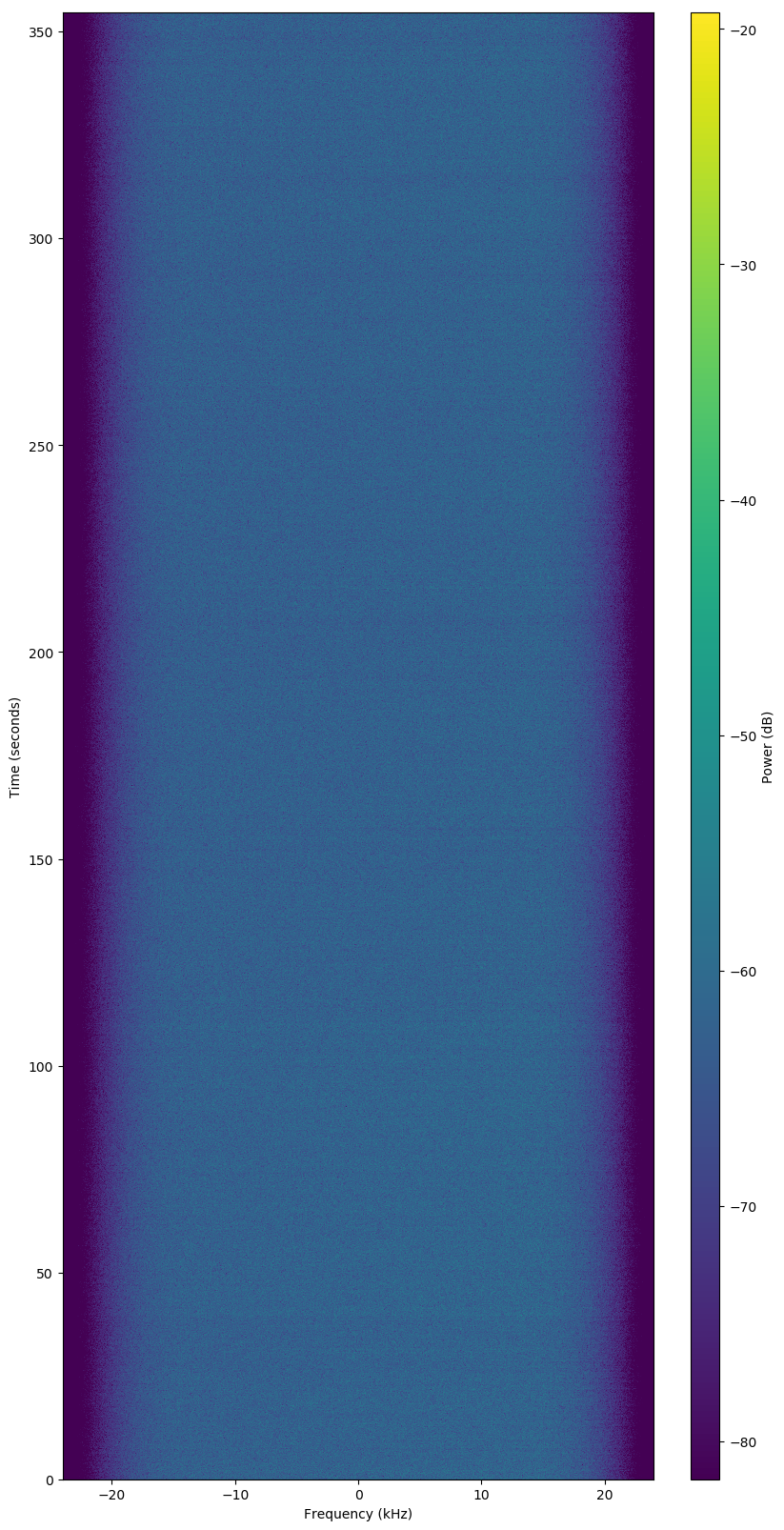
Failed Observation
wut Web
Source code:
Observations
See also:
- https://wiki.satnogs.org/Operation
- https://wiki.satnogs.org/Observe
- https://wiki.satnogs.org/Observations
- https://wiki.satnogs.org/Category:RF_Modes
- Sample observation: https://network.satnogs.org/observations/1456893/
Machine Learning
The system at present is built upon the following:
- Debian Bookworm (testing/12).
- Tensorflow.
- Jupyter Lab.
- Voila.
Learning/testing, results are good. The main AI/ML development is being done in Jupyter.
Jupyter
There Jupyter Lab Notebook files in the notebooks/ subdirectory.
These are producing usable results. Voila is used to convert
Jupyter notebooks into websites.
wut.ipynb--- Machine learning Python script using Tensorflow and Keras in a Jupyter Notebook.wut-predict.ipynb--- Make prediction (rating) of observation from pre-existing model.wut-train.ipynb--- Train models to be using by prediction engine.wut-web.ipynbwut-web-beta.ipynbwut-web-alpha.ipynb
wut scripts
The following scripts are in the repo.
wut--- Feed it an observation ID and it returns if it is a "good", "bad", or "failed" observation.wut-audio-archive--- Downloads audio files from archive.org.wut-audio-sha1--- Verifies sha1 checksums of files downloaded from archive.org.wut-compare--- Compare an observations' current presumably human vetting with awutvetting.wut-compare-all--- Compare all the observations indownload/withwutvettings.wut-compare-tx--- Compare all the observations indownload/withwutvettings using selected transmitter UUID.wut-compare-txmode--- Compare all the observations indownload/withwutvettings using selected encoding.wut-compare-txmode-csv--- Compare all the observations indownload/withwutvettings using selected encoding, CSV output.wut-dl-sort--- Populatedata/dir with waterfalls fromdownload/.wut-dl-sort-tx--- Populatedata/dir with waterfalls fromdownload/using selected transmitter UUID.wut-dl-sort-txmode--- Populatedata/dir with waterfalls fromdownload/using selected encoding.wut-dl-sort-txmode-all--- Populatedata/dir with waterfalls fromdownload/using all encodings.wut-files--- Tells you about what files you have indownloads/anddata/.wut-files-data--- Tells you about what files you have indata/.wut-img-ck.py--- Validate image files are not corrupt with PIL.wut-ml--- Main machine learning Python script using Tensorflow and Keras.wut-ml-auto--- Machine learning Python script using Tensorflow and Keras, auto.wut-ml-load--- Machine learning Python script using Tensorflow and Keras, loaddata/wut.h5.wut-ml-save--- Machine learning Python script using Tensorflow and Keras, savedata/wut.h5.wut-obs--- Download the JSON for an observation ID.wut-ogg2wav--- Convert.oggfiles indownloads/to.wavfiles.wut-rm-random--- Randomly deletes stuff. Very bad.wut-review-staging--- Review all images indata/staging.wut-tf--- Shell script to set variables when launchingwut-tf.py.wut-tf.py--- Distributed learning script to be run on multiple nodes.wut-water--- Download waterfall for an observation ID todownload/[ID].wut-water-range--- Download waterfalls for a range of observation IDs todownload/[ID].wut-worker--- Shell script to set variables when launchingwut-worker.py.wut-worker.py--- Distributed training script to run on multiple nodes.wut-worker-mas--- Shell script to set variables when launchingwut-worker-mas.py.wut-worker-mas.py--- Distributed training script to run on multiple nodes, alt version.
Installation
Installation notes...
There's more docs on a few different setups in the docs/ subdir.
Setup
The scripts use files that are ignored in the git repo. So you need to create those directories:
mkdir -p download
mkdir -p data/train/good
mkdir -p data/train/bad
mkdir -p data/train/failed
mkdir -p data/val/good
mkdir -p data/val/bad
mkdir -p data/val/failed
mkdir -p data/staging
mkdir -p data/test/unvetted
Debian Packages
Install dependencies from Debian.
sudo apt update
sudo apt install curl jq python3-pip graphviz
Install Python Packages
For the machine learning scripts, like wut-ml, Tensorflow
needs to be installed.
You need to add ~/.local/bin to your $PATH:
echo 'PATH=~/.local/bin:$PATH' >> ~/.bashrc
Then log out and back in, or reload ala:
. ~/.bashrc
Update pip to latest pretty version, in local directory. Vary Python package install, suited to taste.
pip install --user --upgrade pip
Make sure you have right pip:
debian@workstation:~$ which pip
/home/debian/.local/bin/pip
Install Python packages:
pip install --user --upgrade -r requirements.txt
Tensorflow KVM Notes
Note, for KVM, pass cpu=host if host has "avx" in /proc/cpuinfo.
Recent versions of Tensorflow can handle many more CPU build options to optimize for speed, such as AVX. By default, Proxmox and likely other virtual machine systems pass kvm/qemu "type=kvm" for CPU type. To use all possible CPU options available on the bare metal server, use "type=host". For more info about this in Proxmox, see CPU Type If you don't have this enabled, CPU instructions will fail or Tensorflow will run slower than it could.
Jupyter
Jupyter is a cute little web interface that makes Python programming easy. It works well for machine learning because you can step through just parts of the code, changing variables and immediately seeing output in the web browser.
Usage
The main purpose of the script is to evaluate an observation, but to do that, it needs to build a corpus of observations to learn from. So many of the scripts in this repo are just for downloading and managing observations.
The following steps need to be performed:
-
Download waterfalls and JSON descriptions with
wut-water-range. These get put in thedownloads/[ID]/directories. -
Organize downloaded waterfalls into categories (e.g. "good", "bad", "failed"). Use
wut-dl-sortscript. The script will sort them into their respective directories under:data/train/good/data/train/bad/data/train/failed/data/val/good/data/val/bad/data/val/failed/
-
Use machine learning script
wut-mlto build a model based on the files in thedata/trainanddata/valdirectories. -
Rate an observation using the
wutscript.
Data Caching Downloads
The scripts are designed to not download a waterfall or make a JSON request
for an observation it has already requested. The first time an observation
is requested, it is downloaded from the SatNOGS network to the download/
directory. That download/ directory is the download cache.
The data/ directory is just temporary files, mostly linked from the
downloads/ directory. Files in the data/ directory are deleted by many
scripts, so don't put anything you want to keep in there.
Preprocessed Files
Files in the preprocess/ directory have been preprocessed to be used
further in the pipeline. This contains .wav files that have been
decoded from .ogg files.
Caveats
This is the first artificial intelligence script I've done, I know little about radio and less about satellites, and I'm not a programmer.
Source License / Copying
Main repository is available here:
License: CC By SA 4.0 International and/or GPLv3+ at your discretion. Other code licensed under their own respective licenses.
Copyright (C) 2019, 2020, 2022 Jeff Moe